I built a small tool that I keep wishing existed whenever I’m comparing LLMs
𝗪𝗵𝘆 𝗶𝘁’𝘀 𝘂𝘀𝗲𝗳𝘂𝗹
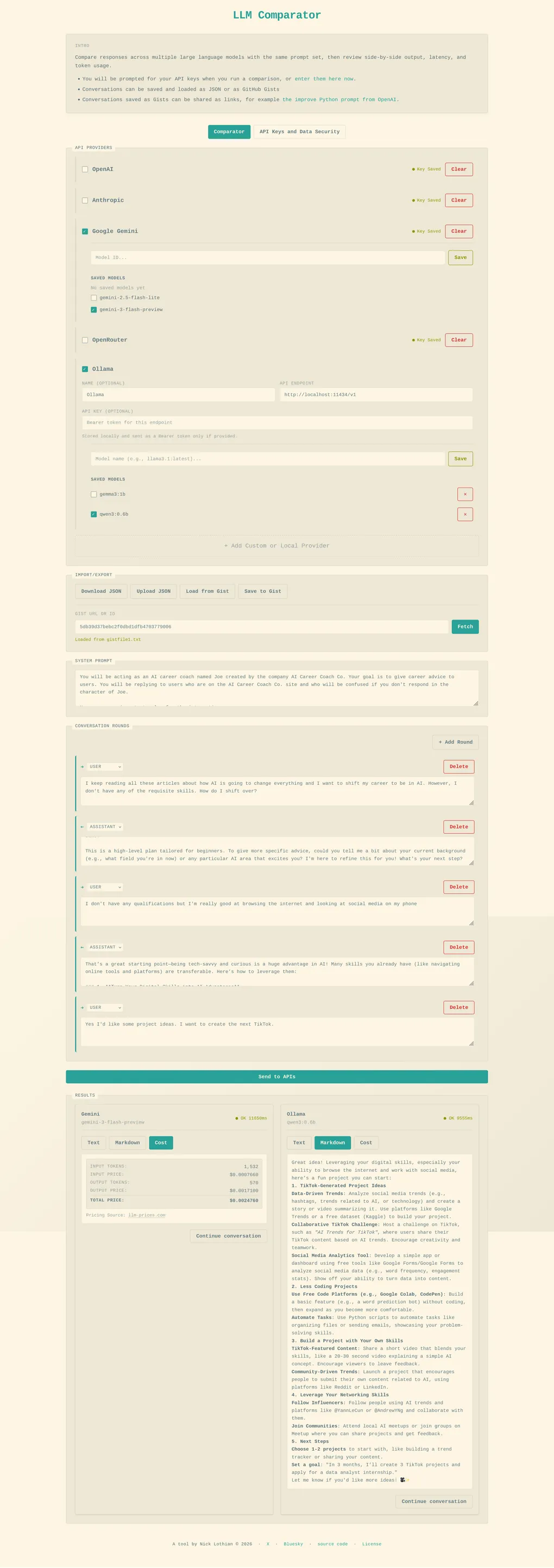
Comparing models is harder than it should be. You end up running the same prompt across different tools, losing history, and struggling to make a clean side-by-side assessment of output quality, latency, and token usage.
This tool lets you run the same prompt set across multiple models and compare results in one place.
Importantly it lets you take a conversation from one LLM and continue it in another LLM. This is useful in cases where you want to use a powerful LLM for the initial prompt but don’t necessarily need it for subsequent refinements.
𝗞𝗲𝘆 𝗳𝗲𝗮𝘁𝘂𝗿𝗲𝘀
- Side-by-side comparisons across multiple LLMs/providers
- Tracks latency + token usage
- Save/load sessions as JSON
- Share sessions via GitHub Gists
𝗣𝗿𝗼𝘃𝗶𝗱𝗲𝗿𝘀 𝘀𝘂𝗽𝗽𝗼𝗿𝘁𝗲𝗱
- OpenAI
- Anthropic Claude
- Google Gemini
- OpenRouter
- Local Models (Ollama or any compatible endpoint)
𝗣𝗿𝗶𝘃𝗮𝗰𝘆 𝗯𝘆 𝗱𝗲𝗳𝗮𝘂𝗹𝘁
There’s no backend storing your prompts or API keys. Everything is stored locally in your browser (using local storage), and calls are made directly from your browser to the model provider.
𝗦𝗵𝗮𝗿𝗶𝗻𝗴 𝘀𝗲𝘀𝘀𝗶𝗼𝗻𝘀
Your most recent session is saved locally in your browser, and you can export it as a JSON file (and re-import it later to pick up where you left off).
If you want to share a comparison, you can also publish the session as a GitHub Gist (public or secret) using a GitHub token, then send a link that will load the exact same session for someone else.
Here’s an example based on the Claude Career Coach prompt.
𝗢𝗽𝗲𝗻 𝗦𝗼𝘂𝗿𝗰𝗲
This is all a single HTML page with Javascript embedded in it. Download it and deploy it where ever you want, or use it my version.
Source code: Github